Model Training And Deployment
1. Environment Setup
1.1 Install YOLO Training Environment
Refer to the official ultralytics installation guide. Install via Docker:
sudo docker pull ultralytics/ultralytics:latest-export
1.2 Enter Docker Container (with GPU)
sudo docker run -it --ipc=host --runtime=nvidia --gpus all -v ./your/host/path:/ultralytics/output ultralytics/ultralytics:latest-export /bin/bash
1.3 Verify YOLO Environment
yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg' device=0
Downloading https://github.com/ultralytics/assets/releases/download/v8.3.0/yolov8n.pt to 'yolov8n.pt': 100% ━━━━━━━━━━━━ 6.2MB 1.6MB/s 4.0s
Ultralytics 8.3.213 🚀 Python-3.11.13 torch-2.8.0+cu128 CUDA:0 (NVIDIA A800 80GB PCIe, 81051MiB)
YOLOv8n summary (fused): 72 layers, 3,151,904 parameters, 0 gradients, 8.7 GFLOPs
Downloading https://ultralytics.com/images/bus.jpg to 'bus.jpg': 100% ━━━━━━━━━━━━ 134.2KB 1.2MB/s 0.1s
image 1/1 /ultralytics/bus.jpg: 640x480 4 persons, 1 bus, 1 stop sign, 64.5ms
Speed: 4.9ms preprocess, 64.5ms inference, 117.6ms postprocess per image at shape (1, 3, 640, 480)
Results saved to /ultralytics/runs/detect/predict
💡 Learn more at https://docs.ultralytics.com/modes/predict
1.4 Install NE301 Project Deployment Environment
To deploy models to NE301 devices, you need to set up the project development environment. Please refer to the Development Environment Setup document in the project root directory for environment setup.
Camthink NeoEyes NE301 AI Camera firmware is now fully open source. Learn more from the NE301 repository.
2. Training & Exporting Models
2.1 Train Model (Optional)
docs\5-neoeyes-ne301-series\3-NE300-MB01-development-board\2-software-guide\0-development-environment-setup.md
# Based on COCO pre-trained model
yolo detect train data=data.yaml model=yolov8n.pt epochs=100 imgsz=256 device=0
# Or train from scratch
yolo detect train data=data.yaml model=yolov8n.yaml epochs=100 imgsz=256 device=0
2.2 Export to TFLite Format
yolo export model=yolov8n.pt format=tflite imgsz=256 int8=True data=data.yaml fraction=0.2
Example Output:
TensorFlow SavedModel: export success ✅ 35.3s, saved as 'yolov8n_saved_model' (40.1 MB)
TensorFlow Lite: starting export with tensorflow 2.19.0...
TensorFlow Lite: export success ✅ 0.0s, saved as 'yolov8n_saved_model/yolov8n_int8.tflite' (3.2 MB)
Export complete (35.4s)
Results saved to /ultralytics
Predict: yolo predict task=detect model=yolov8n_saved_model/yolov8n_int8.tflite imgsz=256 int8
Validate: yolo val task=detect model=yolov8n_saved_model/yolov8n_int8.tflite imgsz=256 data=coco.yaml int8
Visualize: https://netron.app
💡 Learn more at https://docs.ultralytics.com/modes/export
3. Model Quantization
3.1 Download Quantization Tools and Dataset
-
Download quantization scripts and configuration files:
-
Download quantization validation dataset: coco8
3.2 Configure Quantization Parameters
Modify the configuration file user_config_quant.yaml:
model:
name: yolov8n_256
uc: od_coco
model_path: ./yolov8n_saved_model
input_shape: [256, 256, 3]
quantization:
fake: False
quantization_type: per_channel
quantization_input_type: uint8 # float
quantization_output_type: int8 # float
calib_dataset_path: ./coco8/images/val # Calibration dataset, important! Can use part of training set
export_path: ./quantized_models
pre_processing:
rescaling: {scale : 255, offset : 0}
3.3 Execute Quantization
# Install dependencies
pip install hydra-core munch
# Start quantization
python tflite_quant.py --config-name user_config_quant.yaml
Example Output:
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
W0000 00:00:1760435045.538259 834 tf_tfl_flatbuffer_helpers.cc:365] Ignored output_format.
W0000 00:00:1760435045.538286 834 tf_tfl_flatbuffer_helpers.cc:368] Ignored drop_control_dependency.
I0000 00:00:1760435045.567572 834 mlir_graph_optimization_pass.cc:425] MLIR V1 optimization pass is not enabled
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 32/32 [00:05<00:00, 5.46it/s]
fully_quantize: 0, inference_type: 6, input_inference_type: UINT8, output_inference_type: INT8
Quantized model generated: yolov8n_256_quant_pc_ui_od_coco.tflite
3.4 Evaluate Quantized Model (Optional)
yolo val model=./quantized_models/yolov8n_256_quant_pc_ui_od_coco.tflite data=coco.yaml imgsz=256
4. Deploy Model to NE301 Device
4.1 Prepare Model Files
Copy the quantized model file to the project Model/weights/ directory and create or modify the corresponding JSON configuration file (model metadata):
# Navigate to project root directory
cd /path/to/ne301
# Copy model file
cp /your/path/quantized_models/yolov8n_256_quant_pc_ui_od_coco.tflite Model/weights/
# Create corresponding JSON configuration file
# Refer to example files in Model/weights/ directory
Create JSON Configuration File
The JSON configuration file needs to be configured according to the actual model. Key configuration items are as follows:
Key Configuration Items:
-
input_spec: Input specification
width/height: Model input dimensions (e.g., 256)data_type: Input data type (uint8orfloat32)normalization: Normalization parameters (uint8 typically usesmean: [0,0,0],std: [255,255,255])
-
output_spec: Output specification
height/width: Output dimensions (check actual model output, YOLOv8 typically usesheight: 84,width: 1344)data_type: Output data type (int8orfloat32)scale/zero_point: Quantization parameters (must match model quantization parameters)
-
postprocess_type: Post-processing type
pp_od_yolo_v8_uf: uint8 input, float32 outputpp_od_yolo_v8_ui: uint8 input, int8 output (recommended)
-
postprocess_params: Post-processing parameters
num_classes: Number of classes (COCO=80)class_names: List of class names (must match training order)confidence_threshold: Confidence threshold (0.0-1.0)iou_threshold: IoU threshold for NMS (0.0-1.0)max_detections: Maximum number of detection boxestotal_boxes: Total number of boxes (YOLOv8 256x256 typically uses 1344)raw_output_scale/zero_point: Must match quantization parameters inoutput_spec
Reference Examples: Refer to existing JSON files in the Model/weights/ directory as templates. Use tools (such as Netron) to view model output dimensions.
4.2 Build and Deploy Using Makefile
The project provides a Makefile to simplify the build and deployment process:
Step 1: Configure Model
Modify the model configuration in Model/Makefile:
MODEL_NAME = yolov8n_256_quant_pc_ui_od_coco
MODEL_TFLITE = $(WEIGHTS_DIR)/$(MODEL_NAME).tflite
MODEL_JSON = $(WEIGHTS_DIR)/$(MODEL_NAME).json
Step 2: Build Model
# In project root directory
make pkg-model
# Build result is in build/ne301_Model_xxx_pkg.bin
Step 3: Flash to Device
Method 1: Flash directly to the device
# In project root directory
make flash-model
Method 2: Web UI (Recommended)
Updating the model through the Web UI lets you preview the new model quickly without reflashing the firmware.
If you're new to the Web UI features, see the NE301 Quick Start.
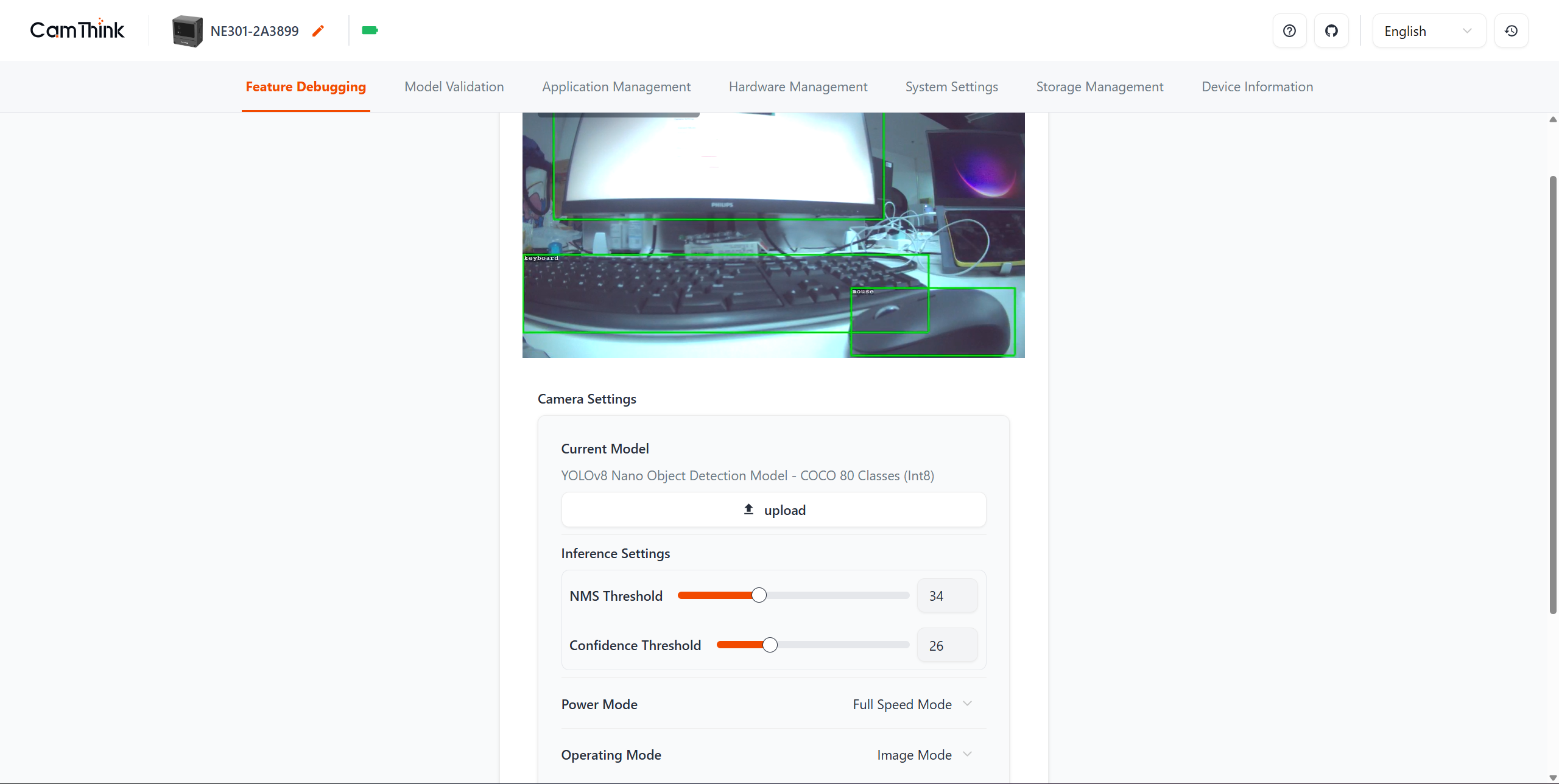
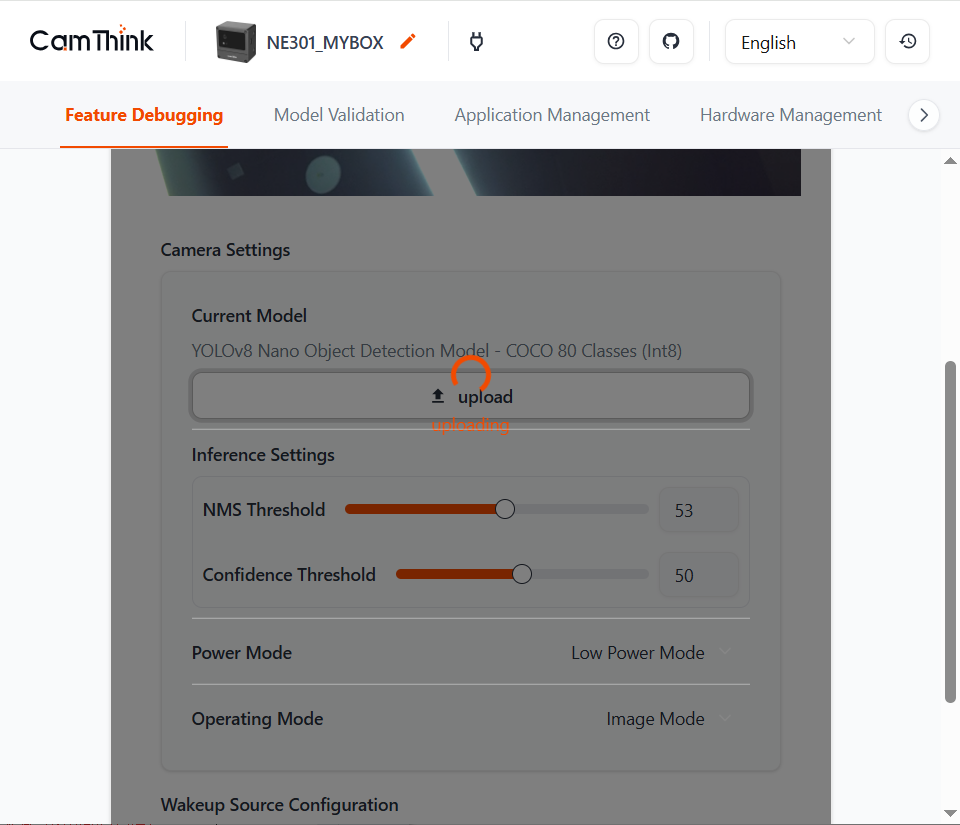
After the device enables the Wi-Fi AP, open the Web UI and go to Feature Debugging on the home page, then click upload to replace the model.
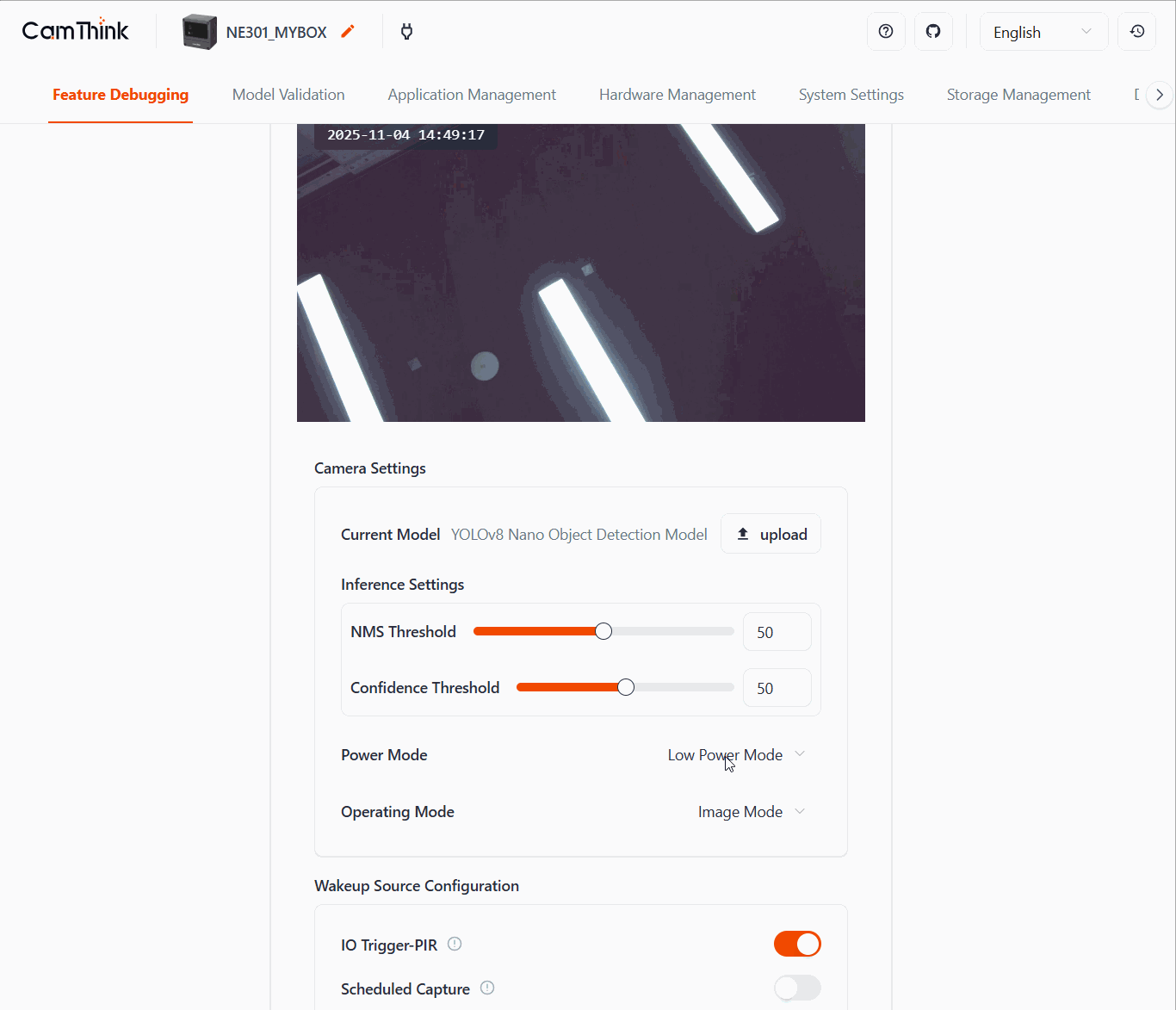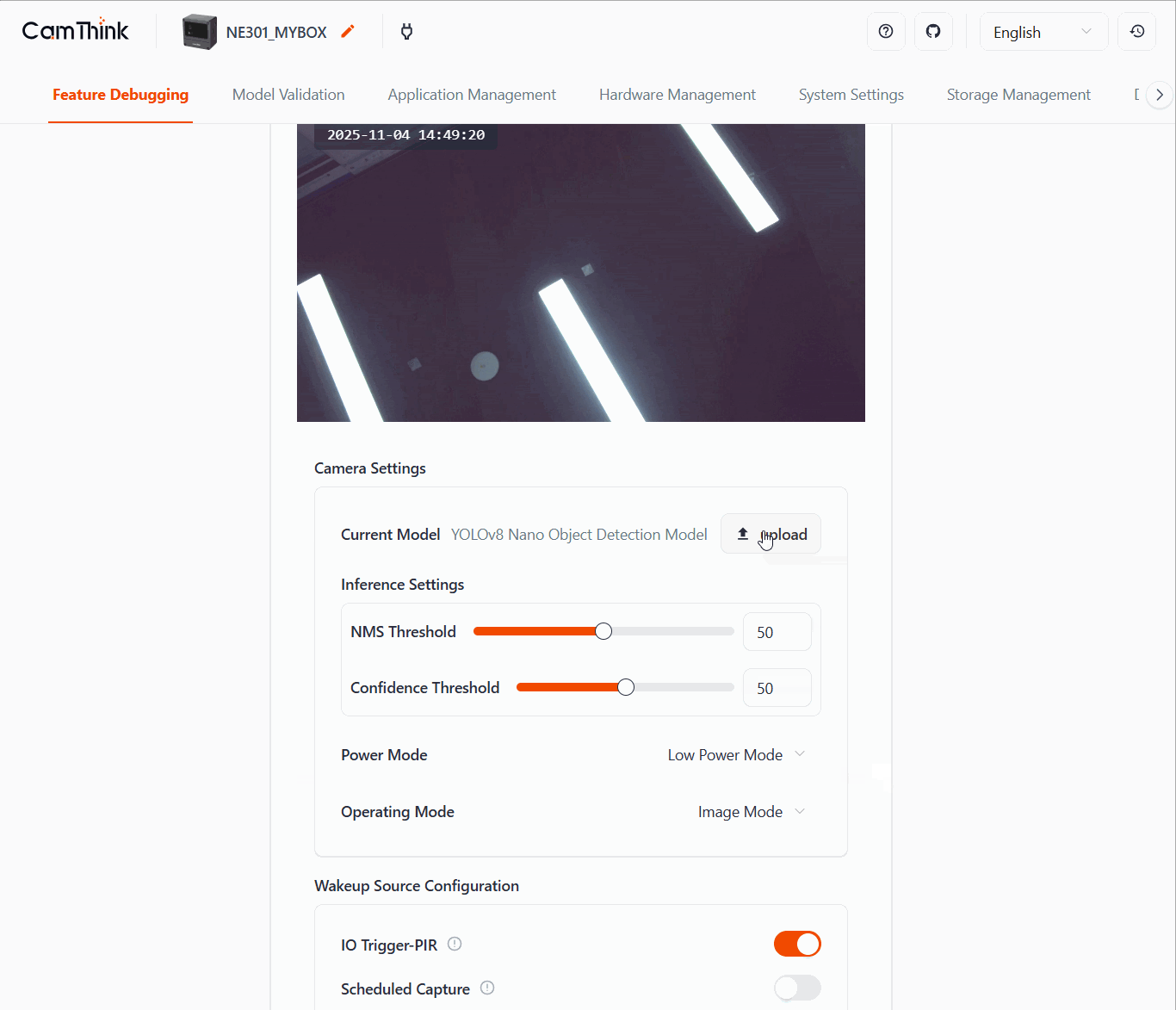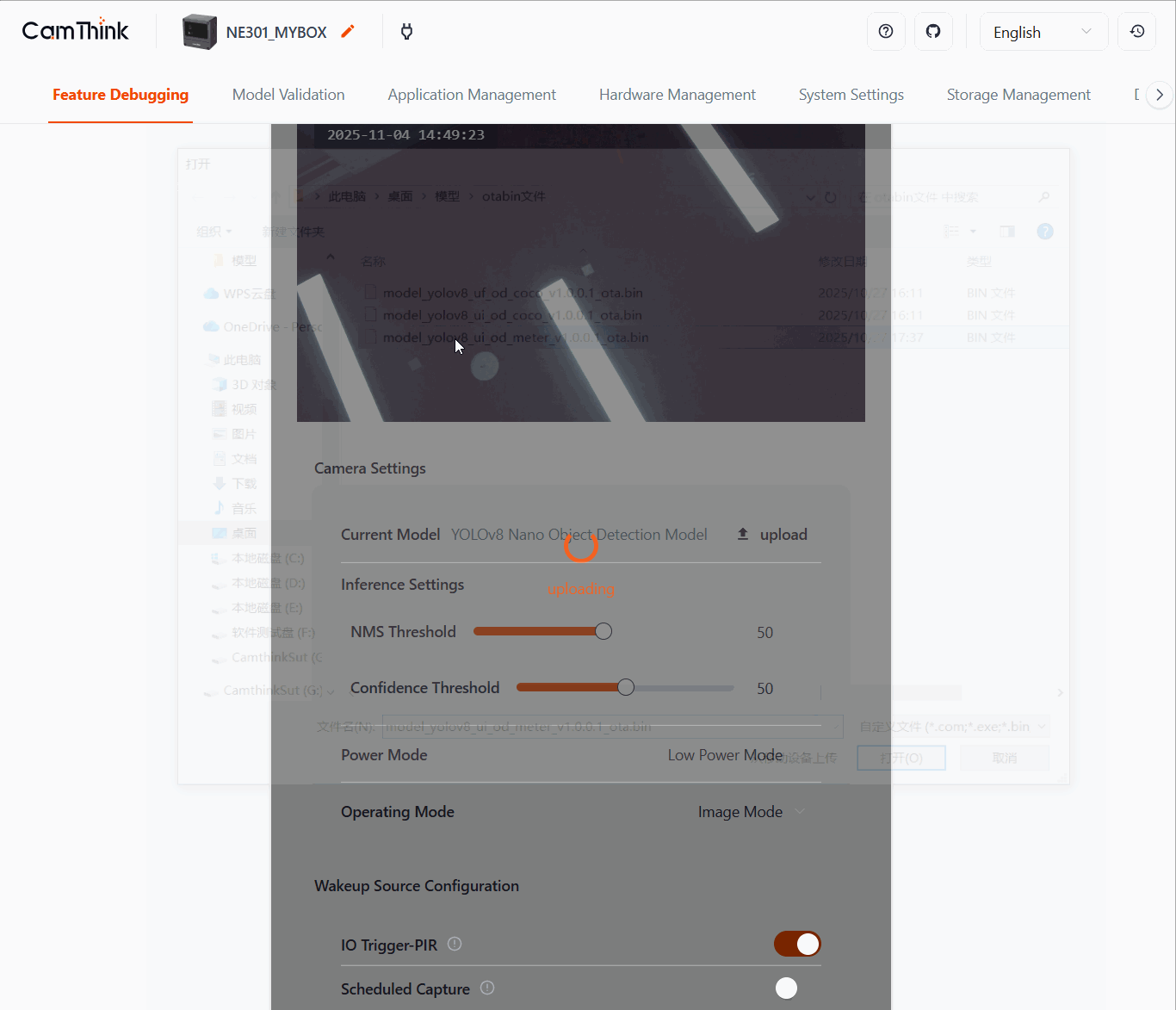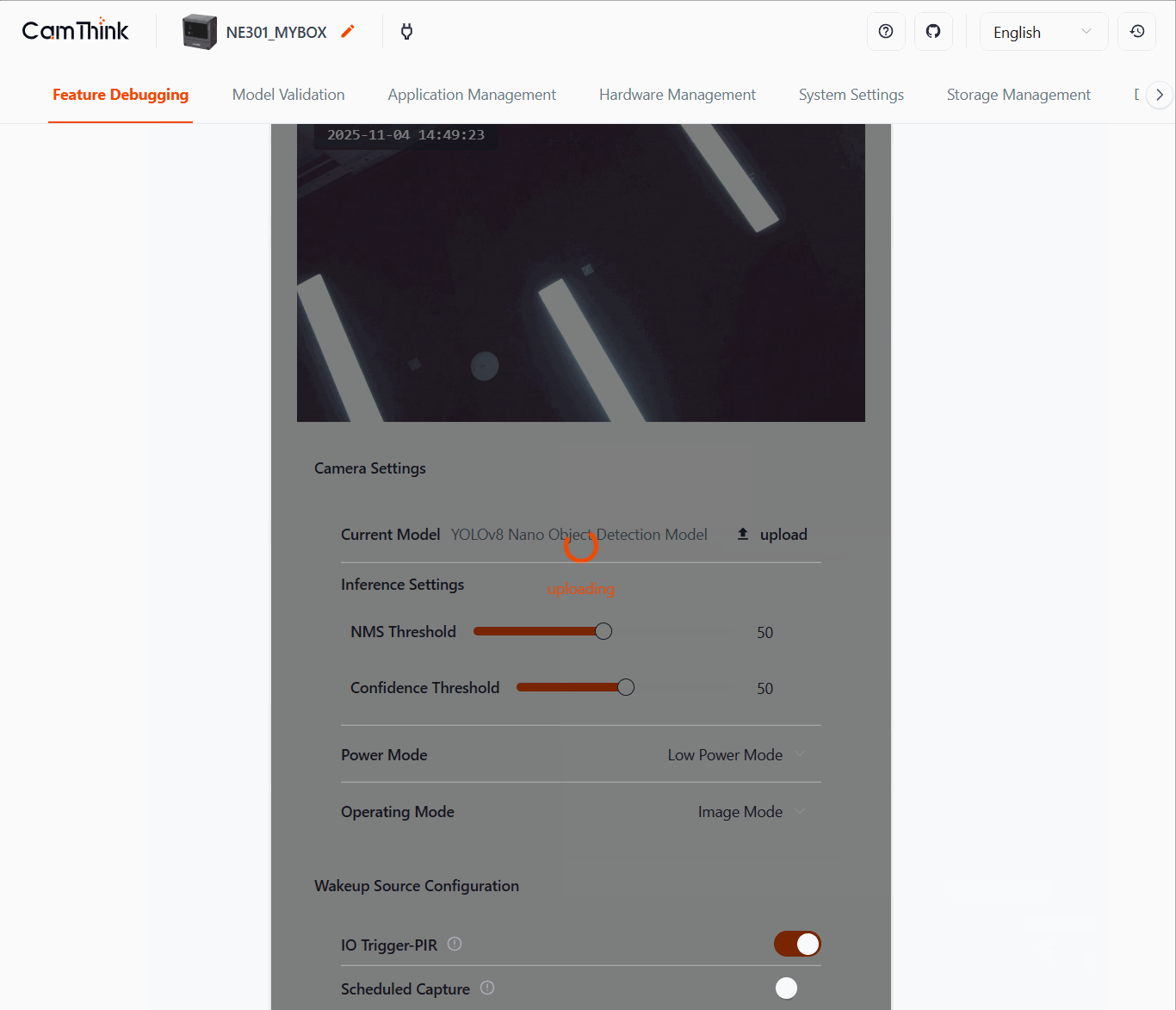
Alternatively, open System Setting → Firmware Upgrade to upload the model binary generated earlier and wait for the device to reload it.