Chatbot
本指南介绍如何使用 Ollama(轻量推理引擎)在 NVIDIA Jetson Orin 设备上本地部署 DeepSeek-R1 大语言模型,实现离线 AI 交互,安装配置简单高效。
1. 概览
像 DeepSeek-R1 这样的 LLM(大语言模型)正逐步成为边缘智能应用的核心。直接在 Jetson Orin 上运行的好处包括:
- 完全离线运行
- 低延迟响应
- 数据隐私增强
本指南内容包括:
- 环境准备
- 安装 Ollama
- 运行 DeepSeek-R1 模型
- 使用 Open WebUI 提供网页界面(可选)
2. 环境准备
硬件需求
| 组件 | 要求 |
|---|---|
| 设备 | Jetson Orin(Nano / NX / AGX) |
| 内存 | ≥ 8GB(更大模型需更高内存) |
| 存储空间 | ≥ 10GB(取决于模型大小) |
| GPU | 支持 CUDA 的 NVIDIA GPU |
软件需求
- Ubuntu 20.04 / 22.04(建议使用 JetPack 5.1.1+)
- NVIDIA CUDA 工具包和驱动(JetPack 已预装)
- Docker(可选,用于容器化部署)
⚙️ 使用
jetson_clocks和检查nvpmodel,启用最大性能模式以获得最佳推理效果。
3. 安装 Ollama(推理引擎)
方式 A:原生脚本安装
curl -fsSL https://ollama.com/install.sh | sh
- 安装 Ollama 服务与 CLI 工具
- 自动处理依赖并配置后台服务
方式 B:基于 Docker 部署
sudo docker run --runtime=nvidia --rm --network=host \
-v ~/ollama:/ollama \
-e OLLAMA_MODELS=/ollama \
dustynv/ollama:r36.4.0
🧩 Docker 版本由 NVIDIA 社区(dustynv)维护,已针对 Jetson 优化
验证 Ollama 是否运行中
ss -tuln | grep 11434
预期输出:
LISTEN 0 128 127.0.0.1:11434 ...
若端口 11434 正在监听,说明 Ollama 服务已启动。
4. 运行 DeepSeek-R1 模型
启动模型
运行 1.5B 参数版本:
ollama run deepseek-r1:1.5b
- Ollama 会自动下载模型(若本地未缓存)
- 命令行中开始交互式对话
💡 根据硬件能力,可将
1.5b替换为8b、14b等版本
模型版本对比
| 版本 | 内存需求 | 备注 |
|---|---|---|
| 1.5B | ~6–8 GB | 适用于 Orin Nano/NX |
| 8B+ | ≥ 16 GB | 需使用 AGX Orin |
| 70B | 🚫 | Jetson 不支持 |
5. 网页界面(Open WebUI)
Open WebUI 提供了基于浏览器的人性化对话界面。
安装 Open WebUI(使用 Docker)
sudo docker run -d --network=host \
-v ${HOME}/open-webui:/app/backend/data \
-e OLLAMA_BASE_URL=http://127.0.0.1:11434 \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
访问 WebUI
浏览器访问:
http://localhost:3000/
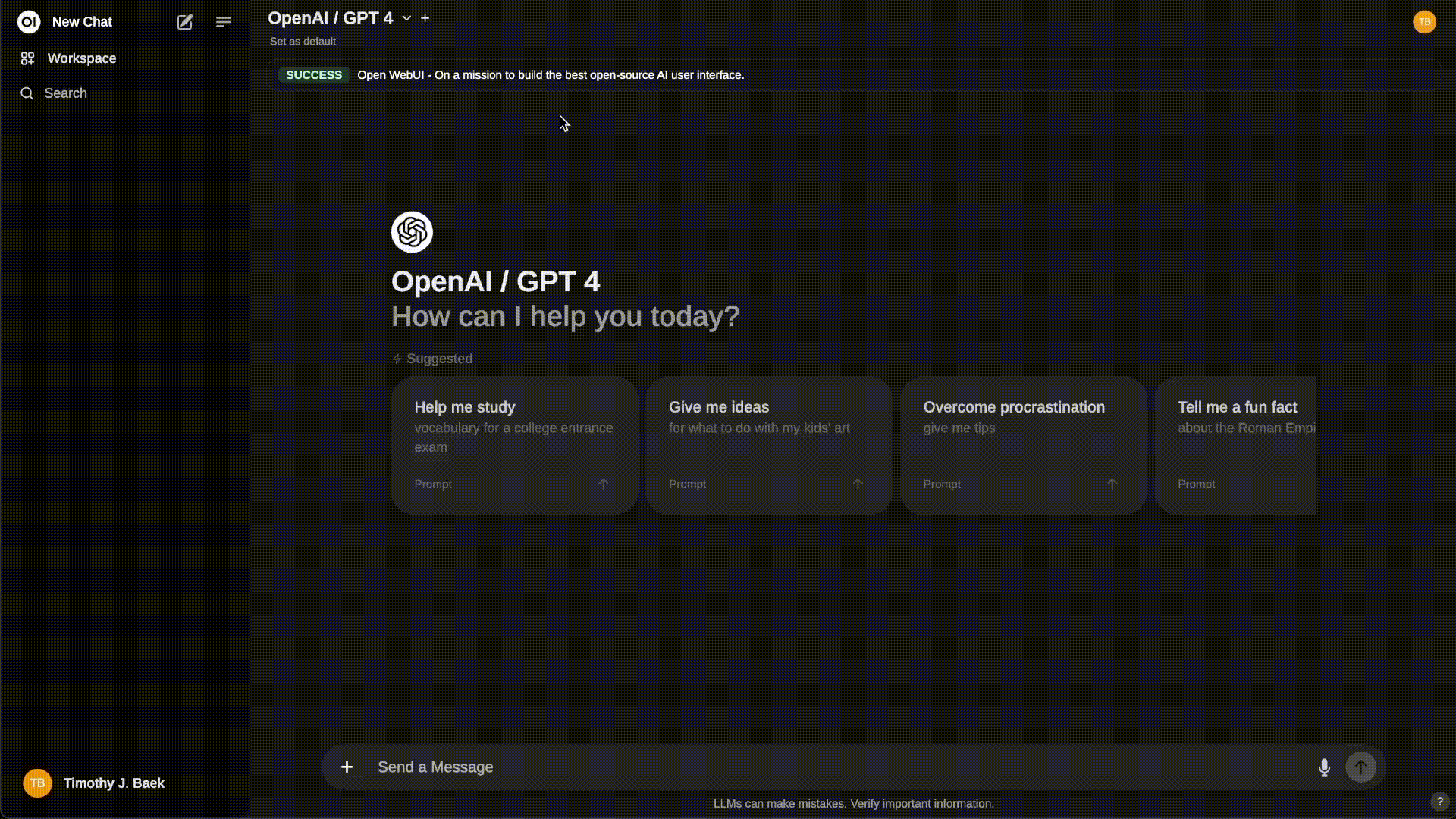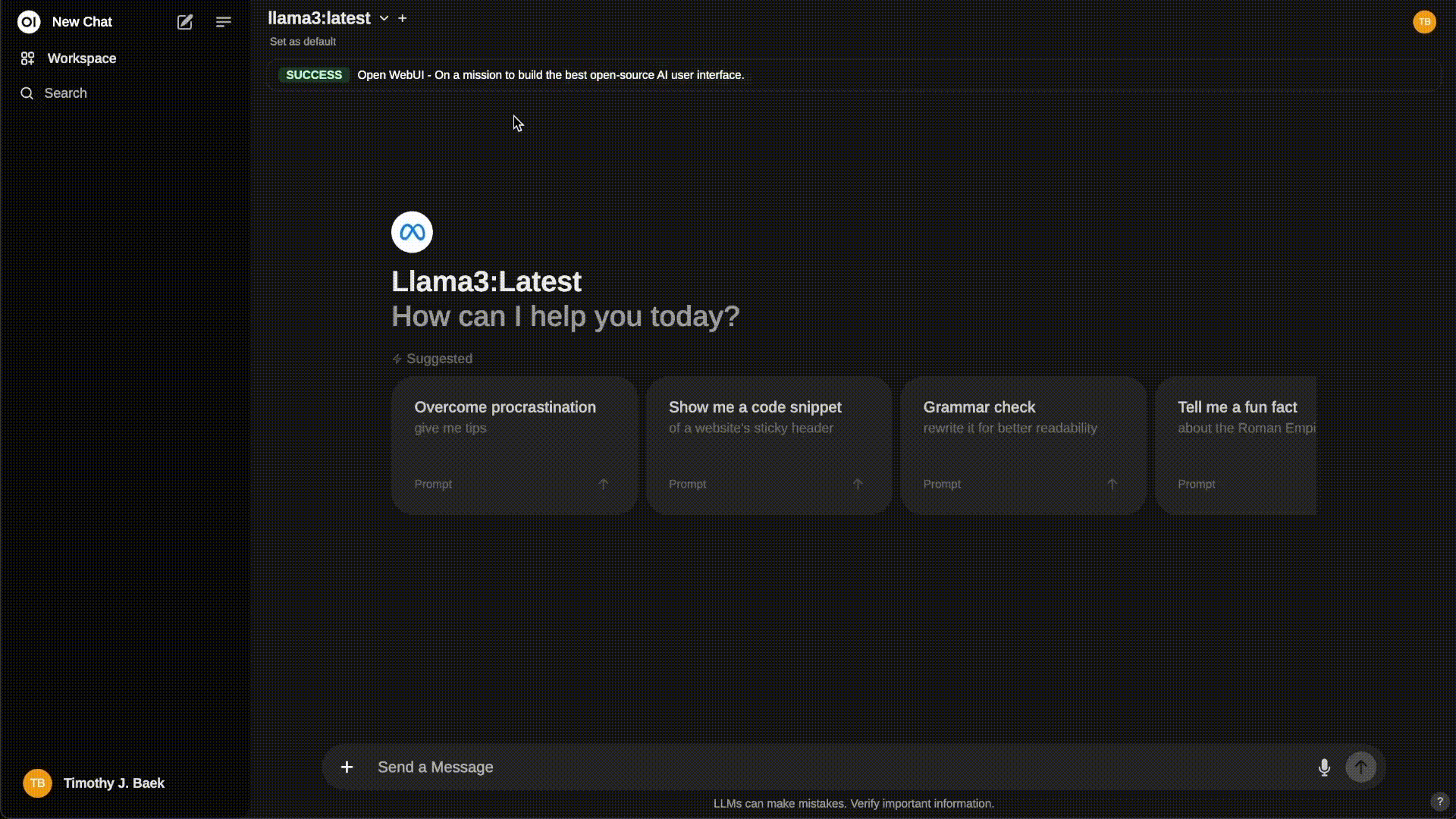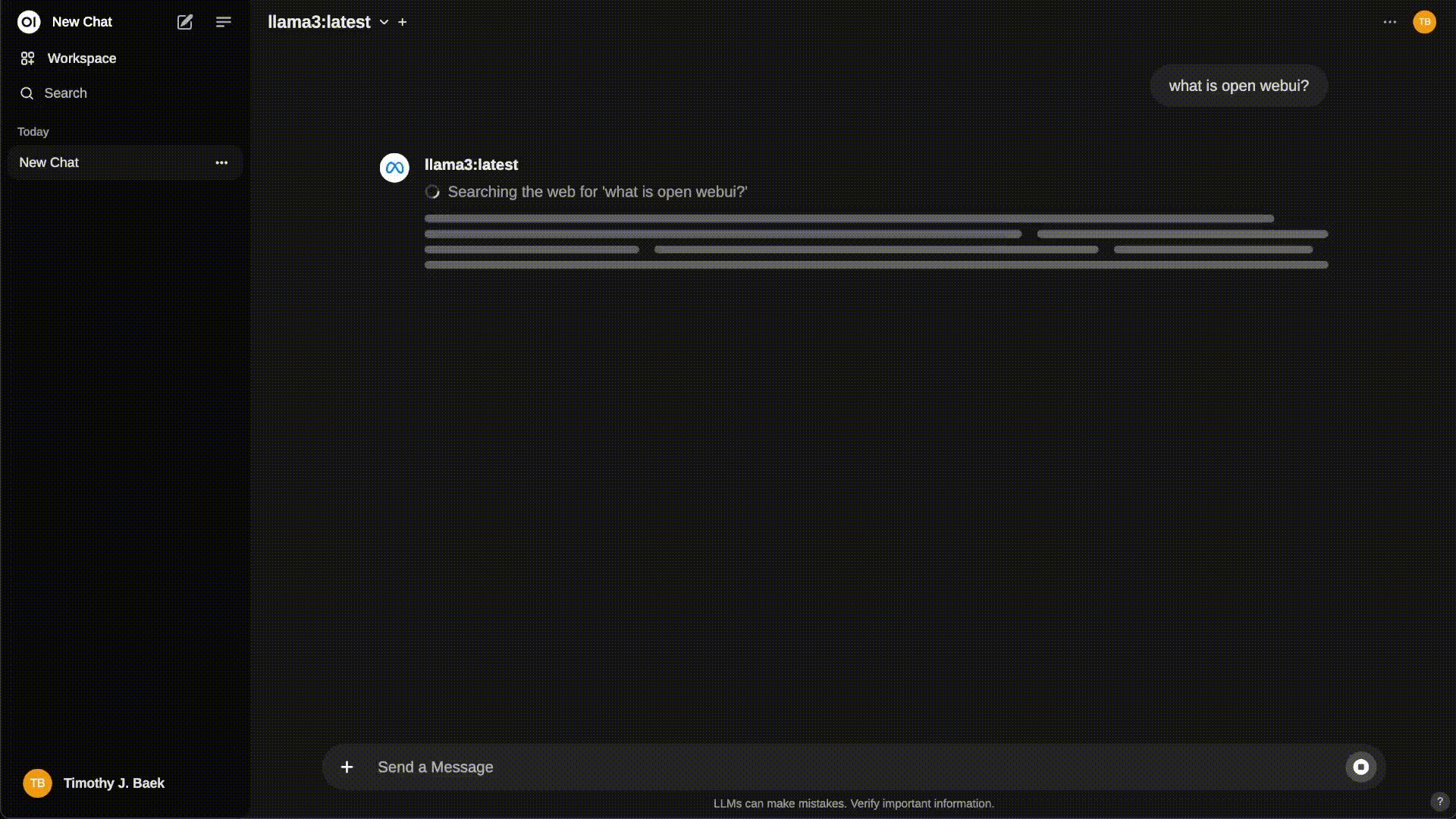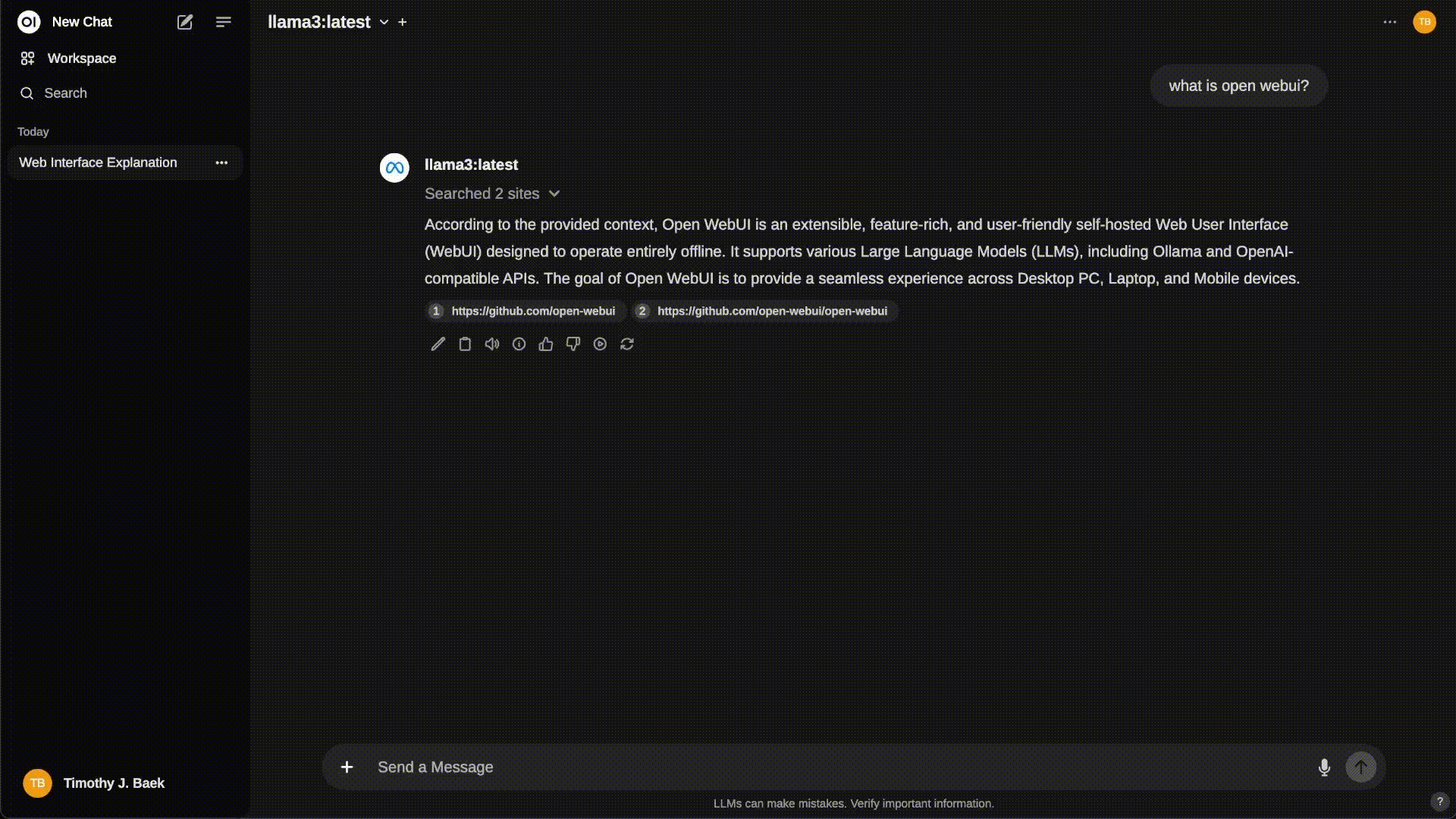
- 在浏览器中与 DeepSeek-R1 模型进行图形化交互
- 可查看对话历史与模型响应内容
6. 性能优化建议
| 优化方向 | 建议 |
|---|---|
| 内存使用 | 使用小模型(如 1.5B)或开启 swap |
| Jetson 性能模式 | 启用 MAXN 模式 + jetson_clocks |
| 模型缓存 | 确保 ~/ollama 目录有足够空间 |
| 运行监控 | 使用 htop、tegrastats 实时查看负载情况 |
📉 首次运行模型时加载时间约为 30 秒至 1 分钟,之后使用缓存加载更快。
7. 故障排查
| 问题 | 解决办法 |
|---|---|
| 端口 11434 未监听 | 重启 Ollama 或检查 Docker 容器状态 |
| 模型加载失败 | 内存不足,尝试使用更小版本(如 1.5B) |
| 无法访问 Web UI | 检查 Docker 是否运行并已连接宿主网络 |
| 找不到 Ollama 命令 | 重新运行安装脚本或将其加入 $PATH |
8. 附录
示例目录结构
~/ollama/ # 模型缓存目录
~/open-webui/ # WebUI 持久化数据