Quick Start
简介
Cinfer是CamThink面向开发者社区开放的通用性Vision AI推理软件,它支持用户执行部署Vision AI推理服务以及提供模型管理,并对外提供标准的OpenAPI服务,适合作为视觉应用开发的图像识别AI组件进行集成,用于调用各种模型来完成图像识别,它具有轻量化、简单的特点,适合快速添加模型进行部署和项目集成。
项目技术栈
- 后端:Python, FastAPI, SQLAlchemy, ONNX Runtime
- 前端:React, TypeScript
- 容器化:Docker, Docker Compose
- Web服务器:Nginx
模型支持
当前仅支持ONNX模型管理及部署,适用于以下ONNX模型任务,如果需要进行模型训练可见「yolo模型训练」,软件操作可见「操作指南」
| 模型类型 | 备注 |
|---|---|
| 分类(Classification) | 支持常见图像/视频分类模型,如动物/物品/场景识别等 |
| 检测(Detection) | 支持目标检测模型(如YOLO、SSD)进行物体定位和分类 |
| 分割(Segmentation) | 支持图像分割模型(如语义分割、实例分割,用于区域分割、车道线等) |
| OCR | 支持文本检测与识别模型,针对图片中的文字提取 |
| 其他自定义ONNX模型 | 支持符合ONNX标准的自定义AI模型(如特定场景算法、特色推理等) |
安装与使用
环境准备
请确认已安装如下环境:
- Docker Engine(推荐版本 20.10.0 及以上),安装详见文档「Install Docker Engine 」
- Docker Compose(推荐版本 v2.0.0 及以上),安装详见文档「Install Docker Compose」
- 如需使用GPU推理,请确保已正确安装 NVIDIA相关驱动 和 NVIDIA Docker 支持,安装详见文档「Install NVIDIA Docker」
项目代码下载
克隆项目到计算机本地
git clone https://github.com/camthink-ai/cinfer.git
 安装成功后进入项目文件夹
安装成功后进入项目文件夹
cd cinfer
使用部署脚本安装
项目提供了一个灵活的部署脚本,文件在根目录下,名称为 deploy.sh ,支持多种部署方式和配置选项,安装和管理命令如下。
# 查看脚本指令
./deploy.sh
# 使用GPU部署
./deploy.sh --gpu yes
# 自定义端口
./deploy.sh --backend-port 8000 --frontend-port 3000
# 指定后端主机
./deploy.sh --host 192.168.100.2
使用deploy.sh脚本进行安装,运行下方命令行安装项目Docker,如果需要其他配置运行请直接运行deploy.sh来查看命令。
执行前请注意检查你本地的3000端口以及8000端口是否有冲突
./deploy.sh --backend-port 8000 --frontend-port 3000

安装完成后即可通过下方地址访问服务:
- Frontend (Local): http://localhost:3000
- Backend API (Local): http://localhost:8000/api
- Backend API (LAN): http://:8000/api
- Backend API (Container): http://backend_cinfer:8000/api
- Swagger Documentation: http://localhost:8000/docs
快速使用
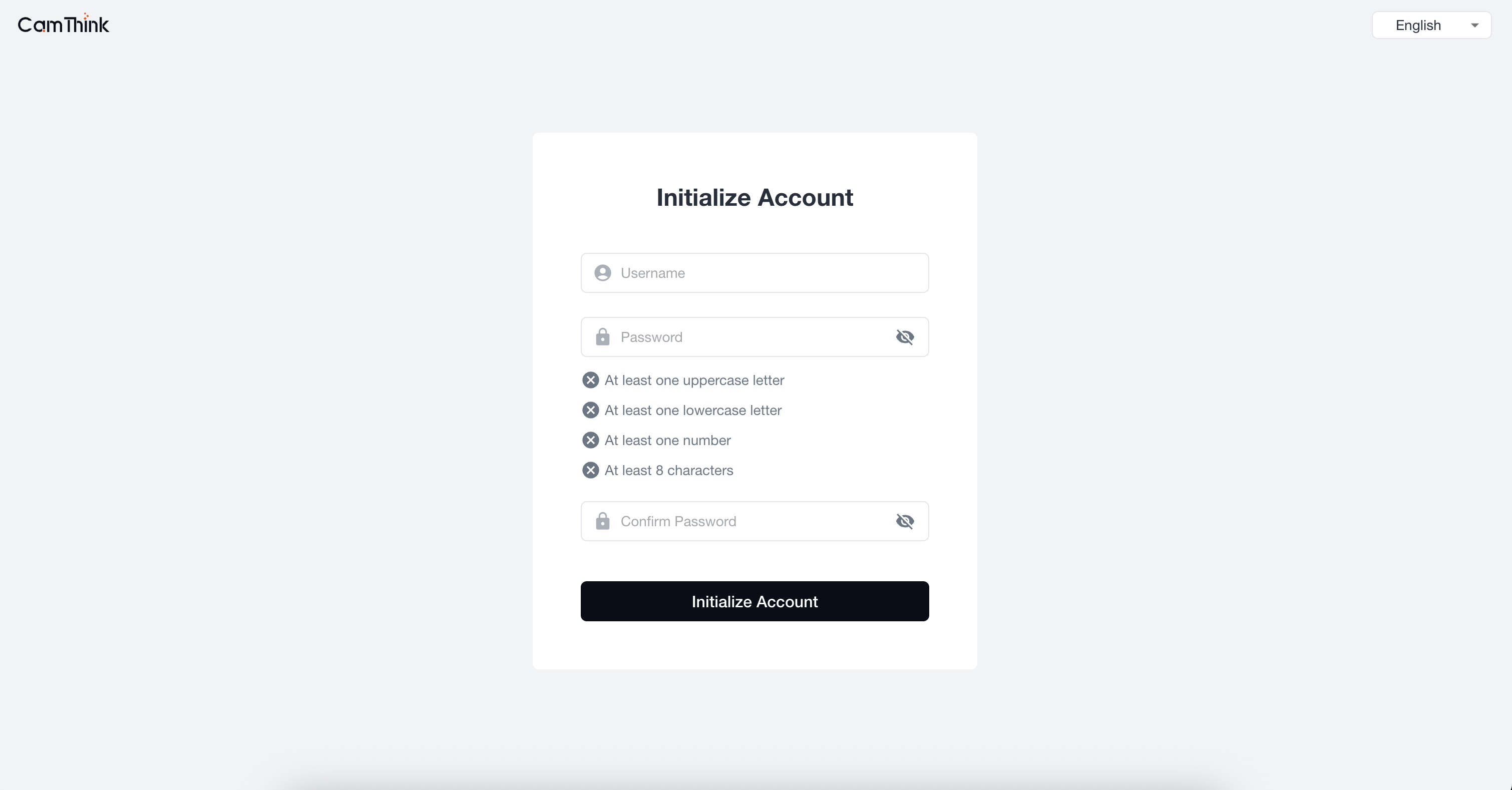
1.注册超级管理员
打开浏览器,输入地址「http://localhost:3000」,访问前端项目,进入初始化管理员设置页,在页面中设置项目的管理员账号及密码,设置成功后进行账户登录进入管理页
2.登录用户
输入设置好的管理员账号和密码,点击登录进入系统页面
3.进入首页
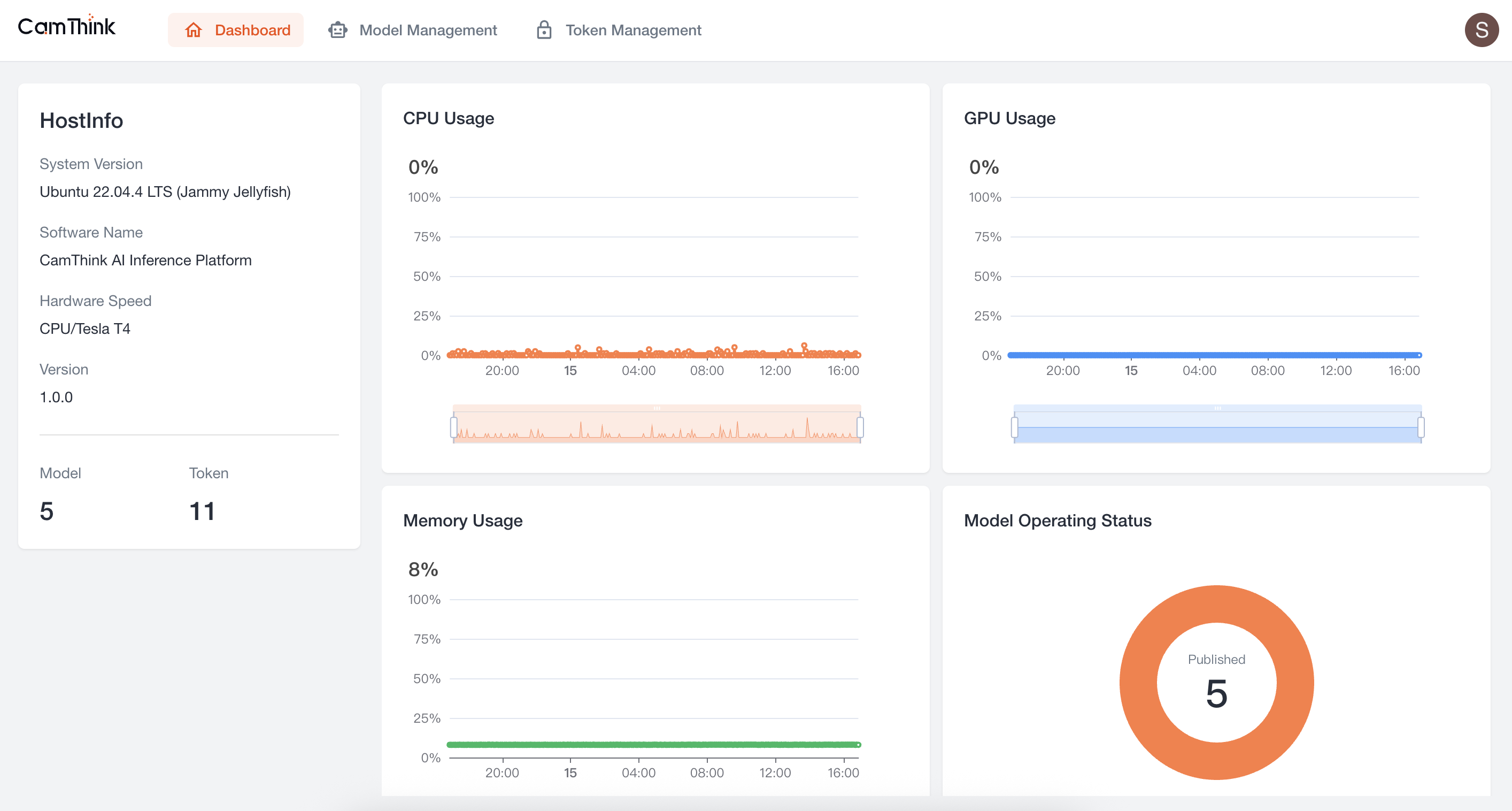
登录成功进入Dashboard,这里可以查看服务的资源占用情况
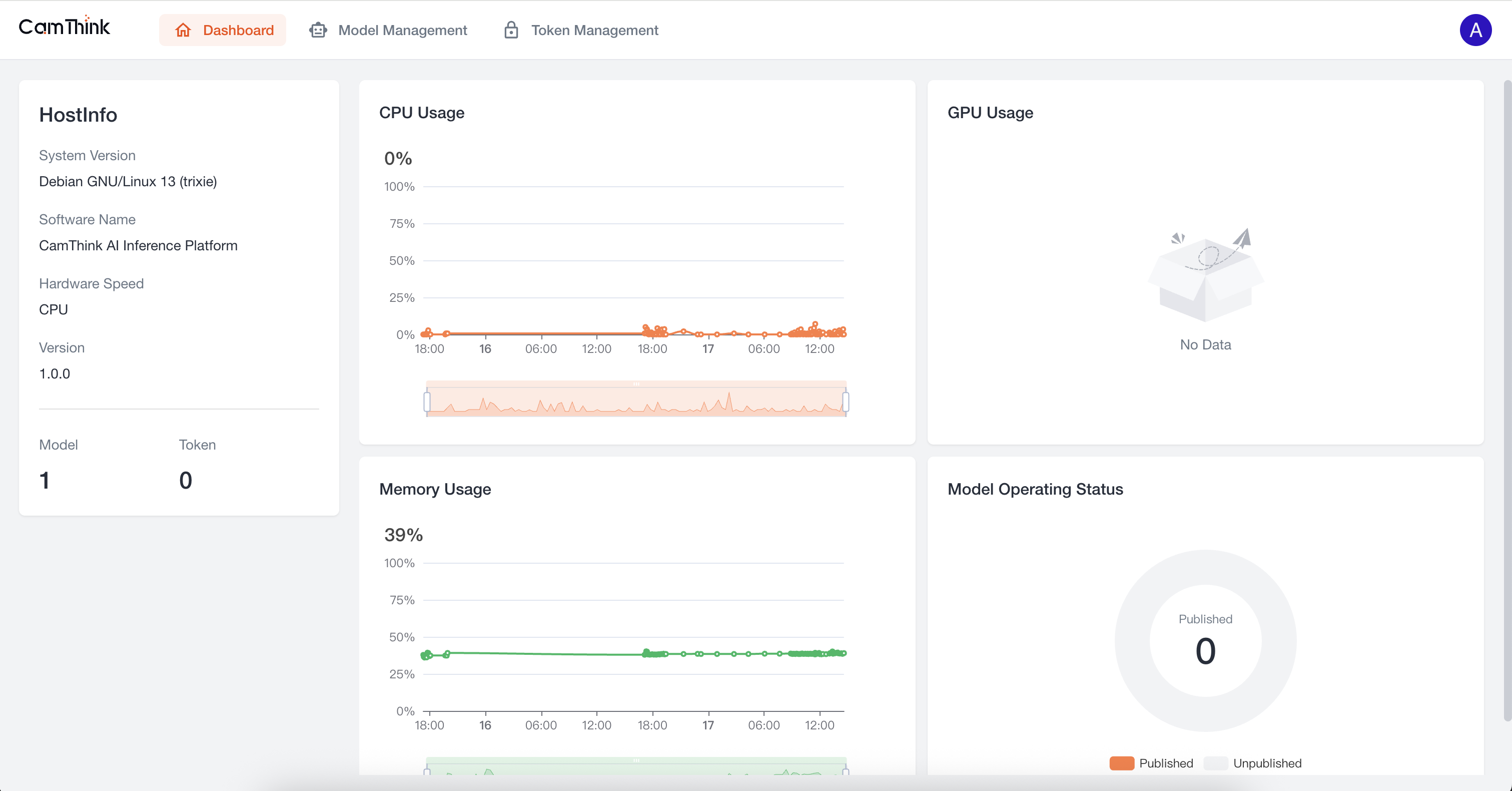
4.查看模型管理
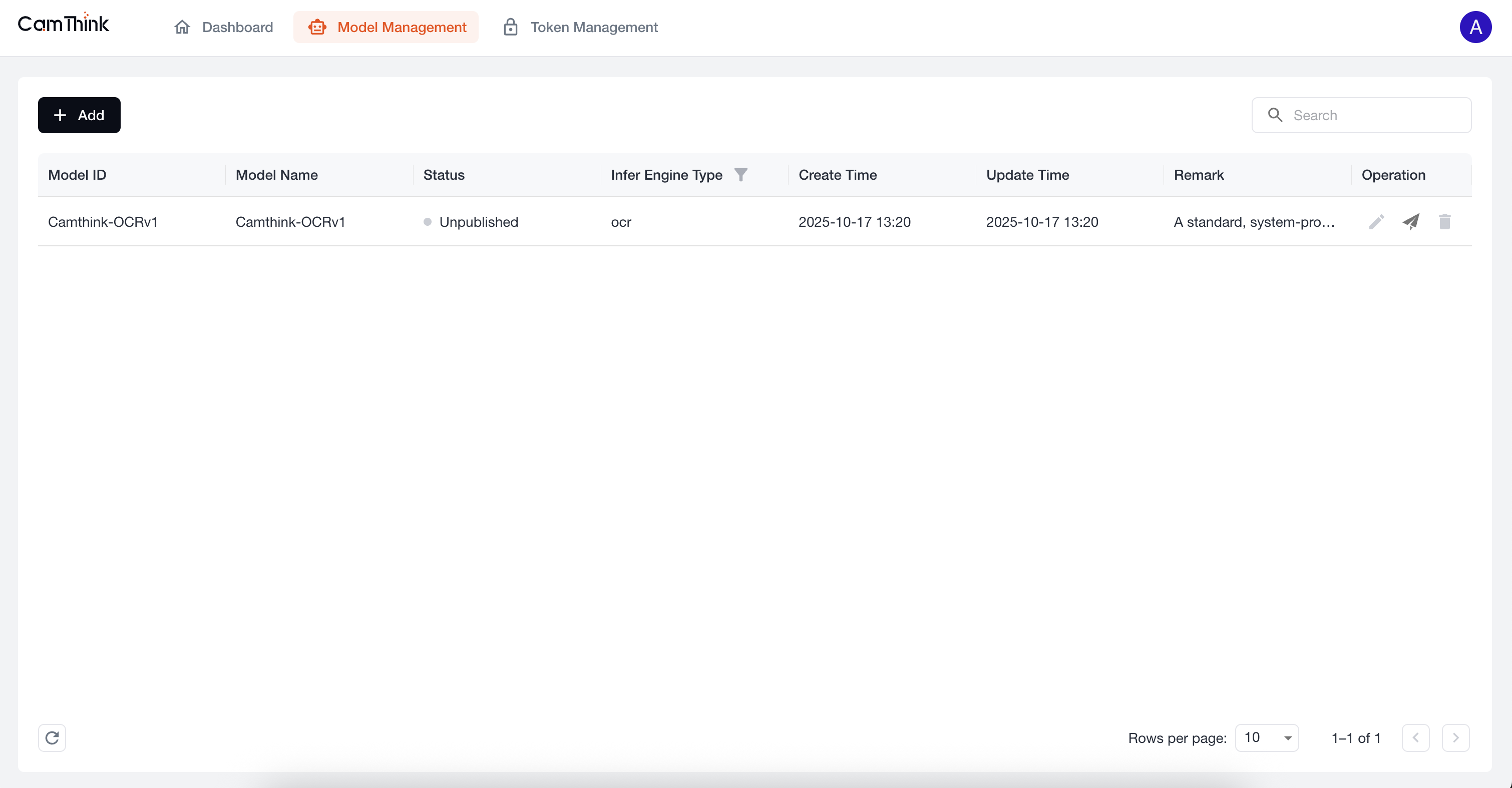
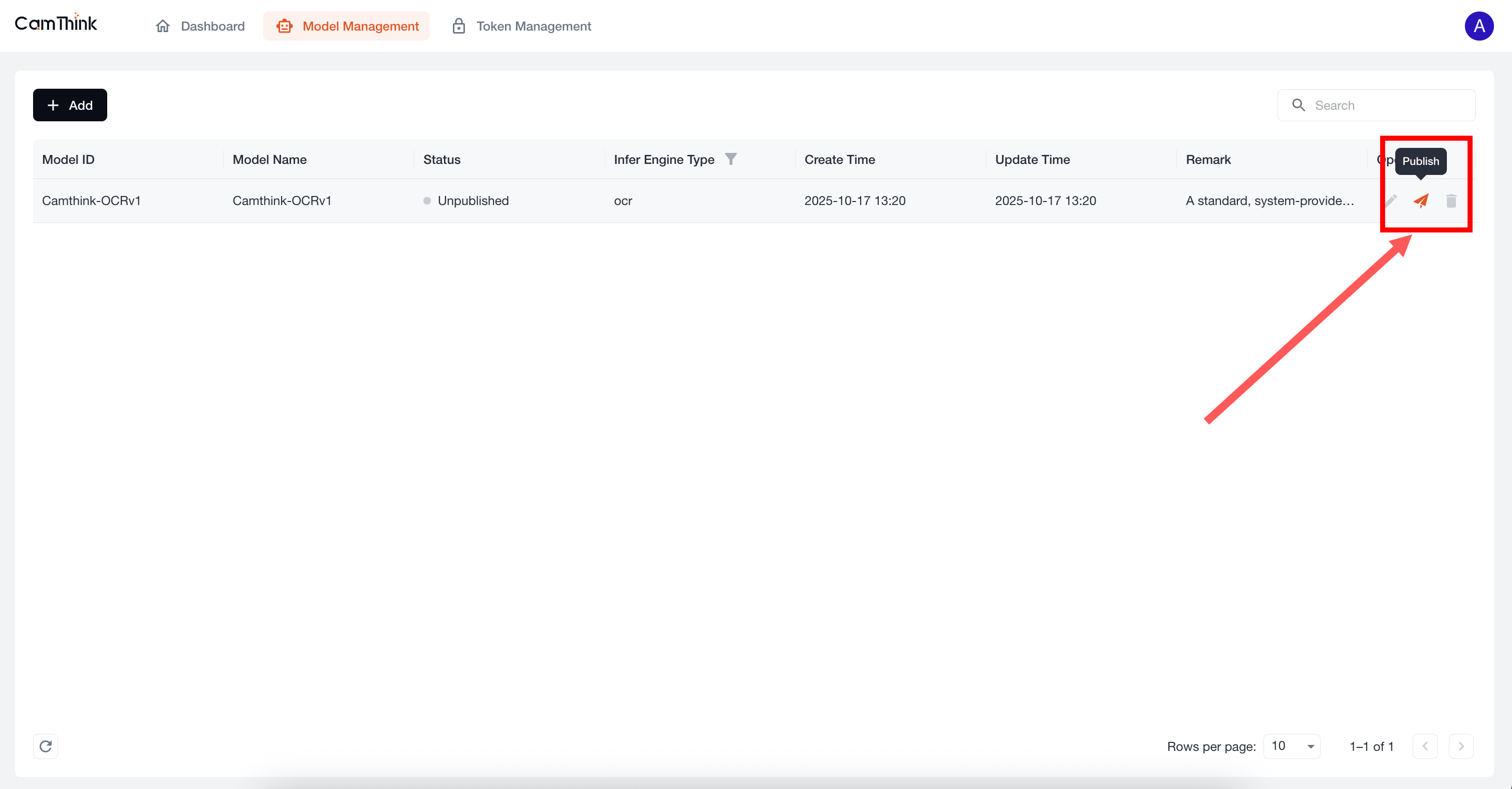
点击 Model Management 菜单,查看模型列表,当前项目内置了一个OCR模型,我们可以进一步测试这个模型来验证服务是否正常,首先我们需要点击此默认模型右侧的「Publish」按钮进行模型发布,先新增一个Toke,查看下方流程
5.新增接口请求Token
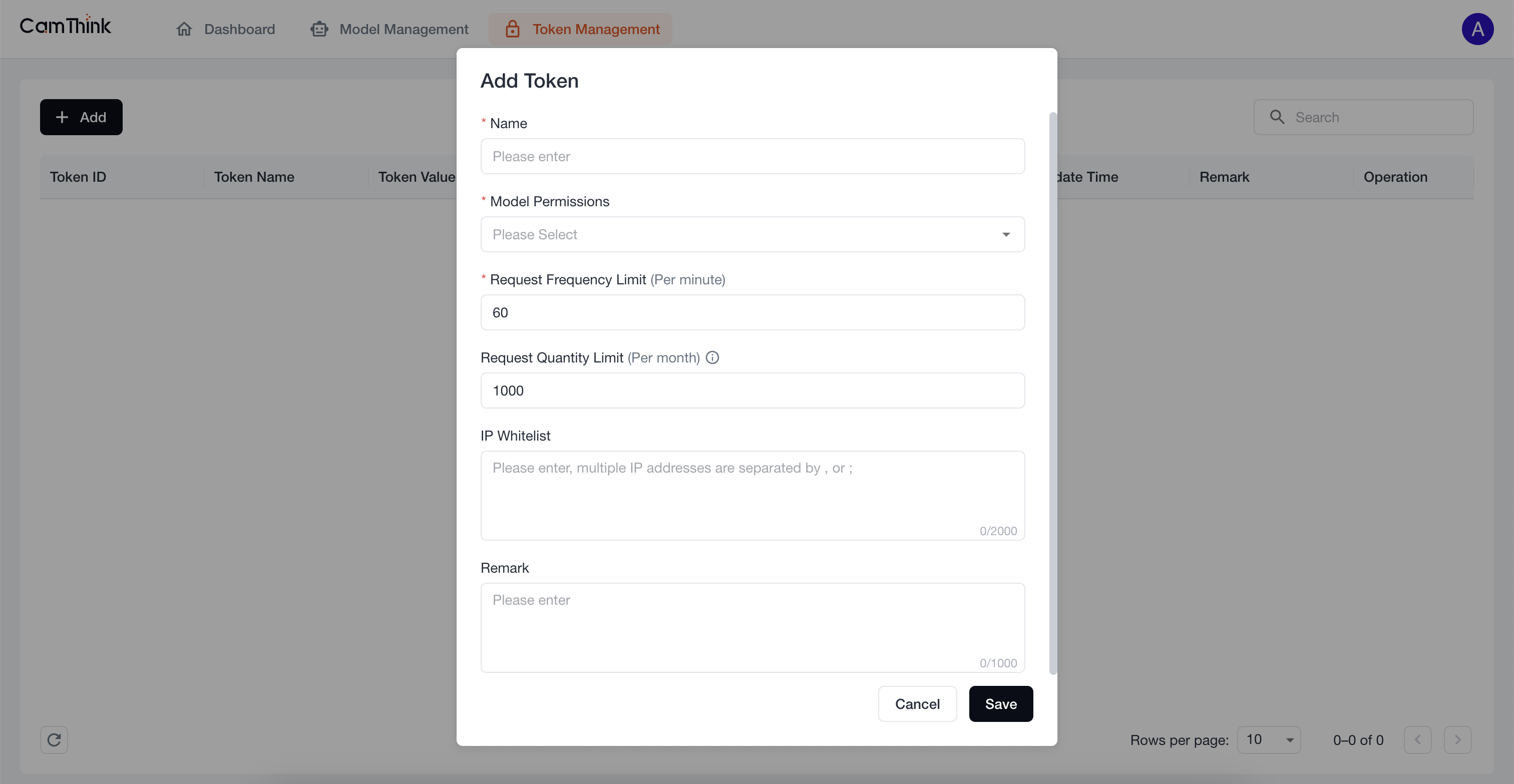
点击 Token Management 菜单,查看Token列表,外部服务必须获取Token才可请求模型接口,点击「Add」按钮,填写表单,输入Token名称,在Model Permissions中下拉选择All Models Selection来设置此Token可访问的模型范围,设置完成后点击「Save」,在弹窗中点击「Copy」按钮复制Token
服务测试
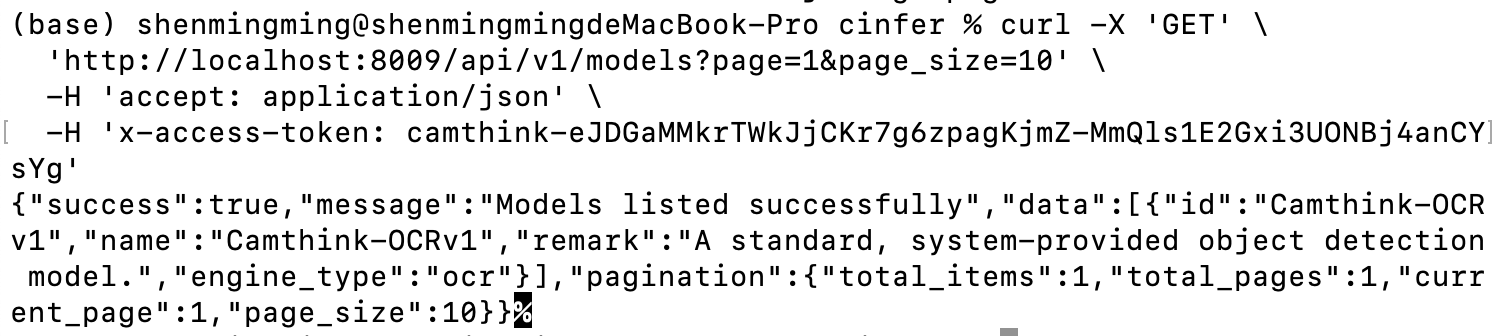
获取模型列表:先用下方命令获取当前模型列表,YOUR_ACCESS_TOKEN替换为你配置的Token,在命令行中输入下方curl命令进行测试,可以获取到当前已发布的内置模型Camthink-OCRv1,我们可以进一步调用接口来查看模型基本信息详情。
curl -X 'GET' \
'http://localhost:8000/api/v1/models?page=1&page_size=10' \
-H 'accept: application/json' \
-H 'x-access-token: YOUR_ACCESS_TOKEN'
请求成功后可以查看到当前所有已发布的模型列表信息,你可以进一步通过下方接口来获取模型的详情。
 获取模型详情:接下来我们将调用模型详情接口来获取模型详细信息,
获取模型详情:接下来我们将调用模型详情接口来获取模型详细信息,model_id用我们前面通过请求模型列表获取到的模型id信息填入,填入你想要查看的模型id,进行下方请求。
curl -X 'GET' \
'http://localhost:8000/api/v1/models/{model_id}' \
-H 'accept: application/json' \
-H 'x-access-token: YOUR_ACCESS_TOKEN'
请求成功后,可以查看

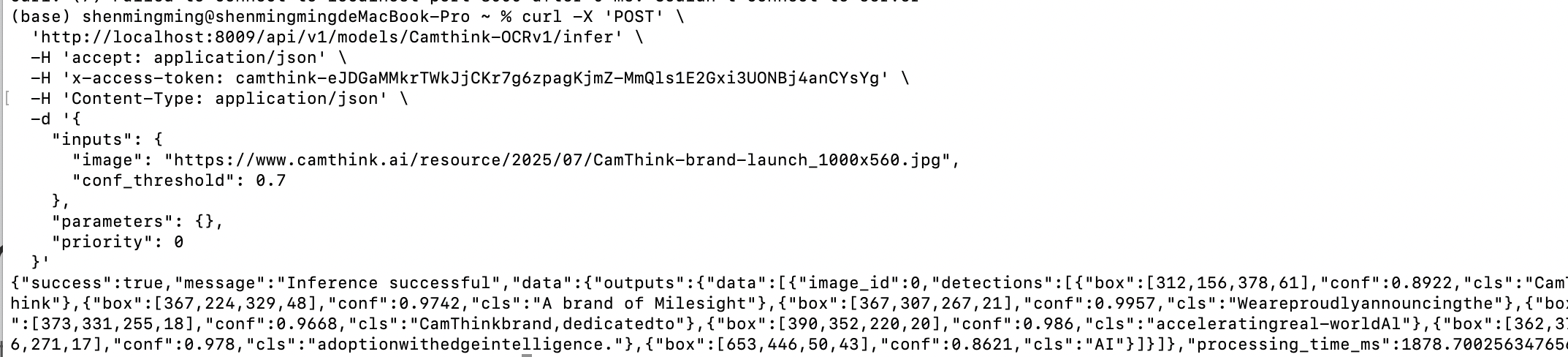
请求模型推理:现在通过模型详情接口我们可以知道模型的输入和输出参数是什么,我们可以根据模型所需的输入参数和输出参数来传递图像来请求AI模型进行图像识别,下方是测试curl,我们可以将YOUR_ACCESS_TOKEN进行替换,并且设置inputs参数,填入目标图像地址以及其他参数来进行一次图片AI推理请�求。
curl -X 'POST' \
'http://localhost:8000/api/v1/models/Camthink-OCRv1/infer' \
-H 'accept: application/json' \
-H 'x-access-token: YOUR_ACCESS_TOKEN' \
-H 'Content-Type: application/json' \
-d '{
"inputs": {
"image": "https://www.camthink.ai/resource/2025/07/CamThink-brand-launch_1000x560.jpg",
"conf_threshold": 0.7
},
"parameters": {},
"priority": 0
}'
可以看到下方请求,接口返回了OCR的识别结果以及每一行的文本内容和box相对于图像像素的坐标位置box,你可以在你的应用界面上绘制它。
 现在你已经完成Cinfer的基本使用教程,可以开始在你的应用程序上对他进行集成。
现在你已经完成Cinfer的基本使用教程,可以开始在你的应用程序上对他进行集成。
应用开发
接口对接
可以通过 http://localhost:8000/docs 查看API文档,进行应用集成对接
BeaverIoT集成
BeaverIoT已经集成了Cinfer推理服务,具体使用详见文档「Beaveriot Integration」
操作指南
软件详细说明及操作使用详见「User Guide」
其他命令
多实例部署
# 部署生产环境
./deploy.sh --name prod --gpu yes
# 同时部署开发环境
./deploy.sh --name dev --backend-port 8009 --frontend-port 3009
管理实例
# 停止实例
./deploy.sh --name prod --action down
# 重启实例
./deploy.sh --name dev --action restart
# 查看日志
./deploy.sh --name prod --action logs
部署脚本选项
| 选项 | 长选项 | 说明 | 默认值 |
|---|---|---|---|
| --arch | 指定 GPU 架构: x86_64 或 jetson。 | 自动检测 | |
-g | --gpu | 是否使用GPU: yes 或 no | no |
-b | --backend-port | 后端服务端口 | 8000 |
-f | --frontend-port | 前端服务端口 | 3000 |
-n | --name | 实例名称 | default |
-a | --action | 操作: up(启动), down(停止), restart(重启), logs(查看日志), build(构建) | up |
-h | --host | 后端主机名或IP地址 | backend |
-r | --rebuild | 是否重新构建镜像: yes 或 no | no |
手动配置
如果需要手动配置部署,可以参考以下步骤:
后端配置
后端环境变量在backend/docker/prod.env文件中配置,主要包括:
- 服务器配置(主机、端口、工作进程数)
- 数据库配置(类型、连接信息)
- 日志配置
- 安全配置(JWT密钥等)
- 模型存储配置
前端配置
前端通过Nginx配置API代理,配置文件位于web/nginx.conf。
数据持久化
数据存储在以下位置:
- 后端数据:挂载到容器的
/app/data目录 - 数据库:默认使用SQLite,存储在
/app/data/cinfer.db - 模型文件:存储在
/app/data/models目录
访问服务
部署完成后,可通过以下地址访问服务:
-
分离部署:
- 前端:
http://<主机IP>:<前端端口>(默认为3000) - 后端API:
http://<主机IP>:<后端端口>/api(默认为8000) - Swagger文档:
http://<主机IP>:<后端端口>/docs
- 前端:
-
集成部署:
- 应用:
http://<主机IP>:<集成端口>(默认为8080) - API:
http://<主机IP>:<集成端口>/api - Swagger文档:
http://<主机IP>:<集成端口>/docs
- 应用:
常见问题
1. 容器无法启动
检查Docker日志以获取详细错误信息:
docker logs <容器ID或名称>
2. 前端无法连接后端API
确保Nginx配置中的proxy_pass指向正确的后端地址和端口。
3. GPU支持问题
确保主机已正确安装NVIDIA Docker支持,并且GPU驱动版本兼容。
4. 修改代码后需要重新构建
如果修改了Dockerfile或源代码,需要使用--rebuild yes参数重新构建镜像:
./deploy.sh --rebuild yes