配置 LLM 后端
NeoMind 的 AI Agent 与 AI Chat 依赖 LLM 后端理解自然语言并执行指令。本文介绍如何通过 Web UI 或 CLI 配置本地或云端 LLM。
后端总览
NeoMind 支持 10+ 种 LLM 后端,按部署形态分两类:
| 类别 | 后端 | 默认模型 | 备注 |
|---|---|---|---|
| 本地(推荐入门) | Ollama | qwen3.5:4b | 默认后端,完全离线 |
| 本地 | llama.cpp | 启动时加载 | 自托管 llama-server |
| 云端 | OpenAI | gpt-4o-mini | 需 API Key |
| 云端 | Anthropic | claude-3-5-sonnet | 需 API Key |
| 云端 | gemini-1.5-flash | 需 API Key | |
| 云端 | xAI | grok-beta | 需 API Key |
| 云端 | Qwen(阿里) | qwen-max-latest | 需 DashScope Key |
| 云端 | DeepSeek | deepseek-v3 | 需 API Key |
| 云端 | GLM(智谱) | glm-4-plus | 需 API Key |
| 云端 | MiniMax | m2-1-19b | 需 API Key |
| 云端 | Custom | 任意 | OpenAI 兼容端点 |
推荐:本地用 Ollama +
qwen3.5:4b(4B 参数,平衡速度与效果,8GB 内存可流畅运行)。需要更强能力或多模态时再接入云端。
方式一:Web UI 配置(推荐)
Step 1:安装 Ollama 并拉取模型(本地后端)
按 ollama.com 指引安装。安装后 Ollama 默认监听 http://localhost:11434。
# 安装 Ollama(macOS / Linux)
curl -fsSL https://ollama.com/install.sh | sh
# 推荐模型(中文 + 工具调用 + 128K 上下文)
ollama pull qwen3.5:4b
# 如需视觉能力(可读图),额外拉取视觉模型
ollama pull qwen3.5:4b-vl # 或 llava / minicpm-v 等
注意:请使用
qwen3.5:4b。文档历史版本提到的ministral-3:3b/deepseek-r1:7b已不再推荐——前者工具调用不稳定,后者体积过大且在边缘硬件上速度欠佳。
跳过此步如果使用云端后端(OpenAI / Anthropic / GLM 等)。
Step 2:进入 LLM 后端设置
打开 Settings(设置) → LLM Backends(LLM 后端):
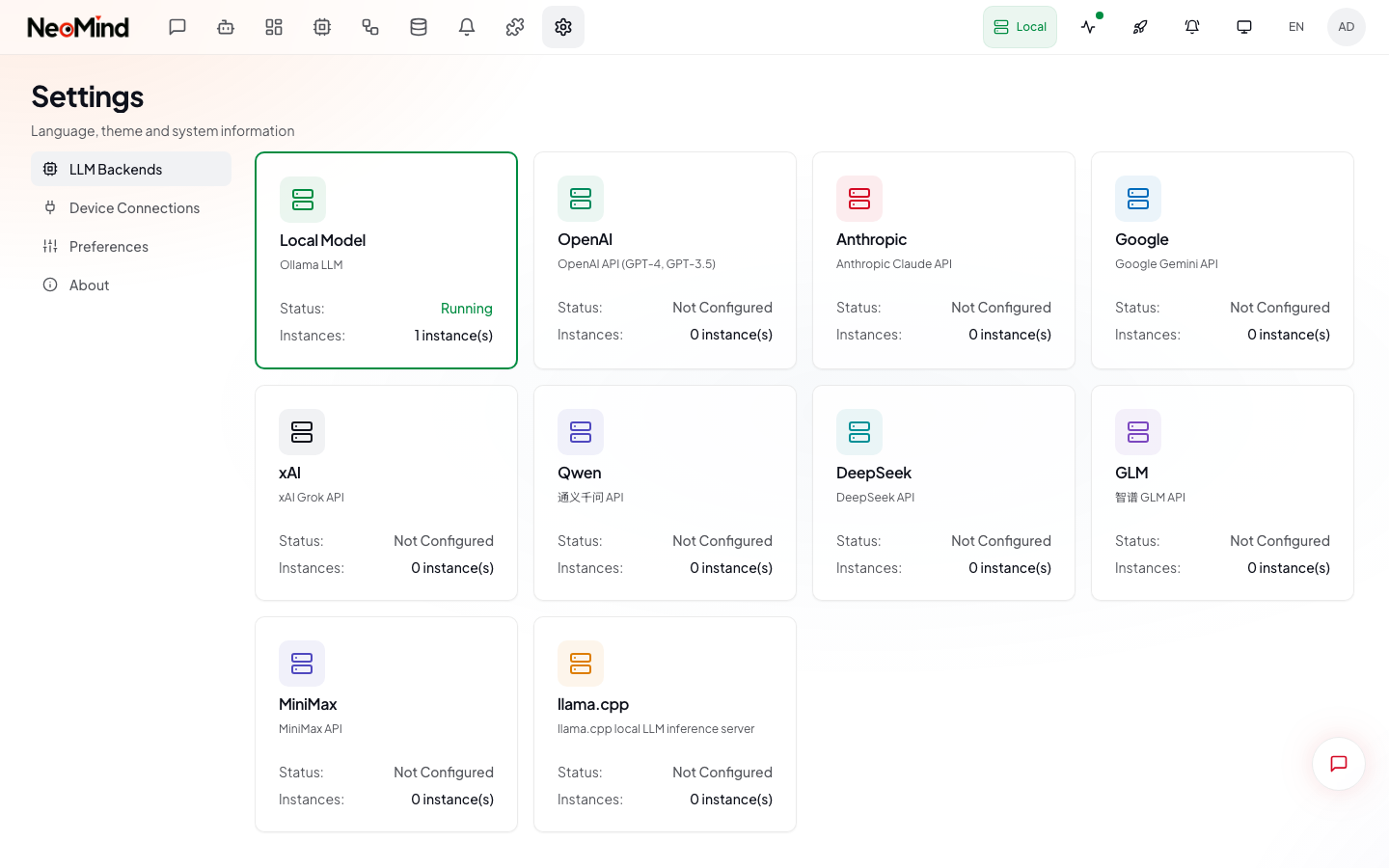
点击 Add Backend(添加后端) 进入配置表单。
Step 3:填写后端信息
Ollama(本地)
| 字段 | 值 |
|---|---|
| 类型 | Ollama |
| Endpoint | http://localhost:11434(默认;远程主机替换为对应 IP) |
| 模型 | qwen3.5:4b(与 ollama pull 的名称一致) |
| Stream | 开启(推荐,流式输出体验更好) |
云端(以 OpenAI 为例)
| 字段 | 值 |
|---|---|
| 类型 | OpenAI(或 Anthropic / Google / Qwen / …) |
| API Key | 你的 API Key(如 sk-...) |
| Base URL | 留空用官方;自建网关时填自定义端点 |
| 模型 | gpt-4o-mini(或 gpt-4o / gpt-4-turbo 等) |
国内厂商:Qwen / DeepSeek / GLM / MiniMax 均使用 OpenAI 兼容协议,NeoMind 内置各厂商的默认 endpoint,只需填 API Key 与模型名即可。
Custom(自定义 OpenAI 兼容端点)
如果你用的是 vLLM、Together AI、OpenRouter 等自建或第三方网关,选 Custom,填入:
base_url:网关地址(如https://api.openrouter.ai/v1)api_key:网关 Keymodel:网关暴露的模型名
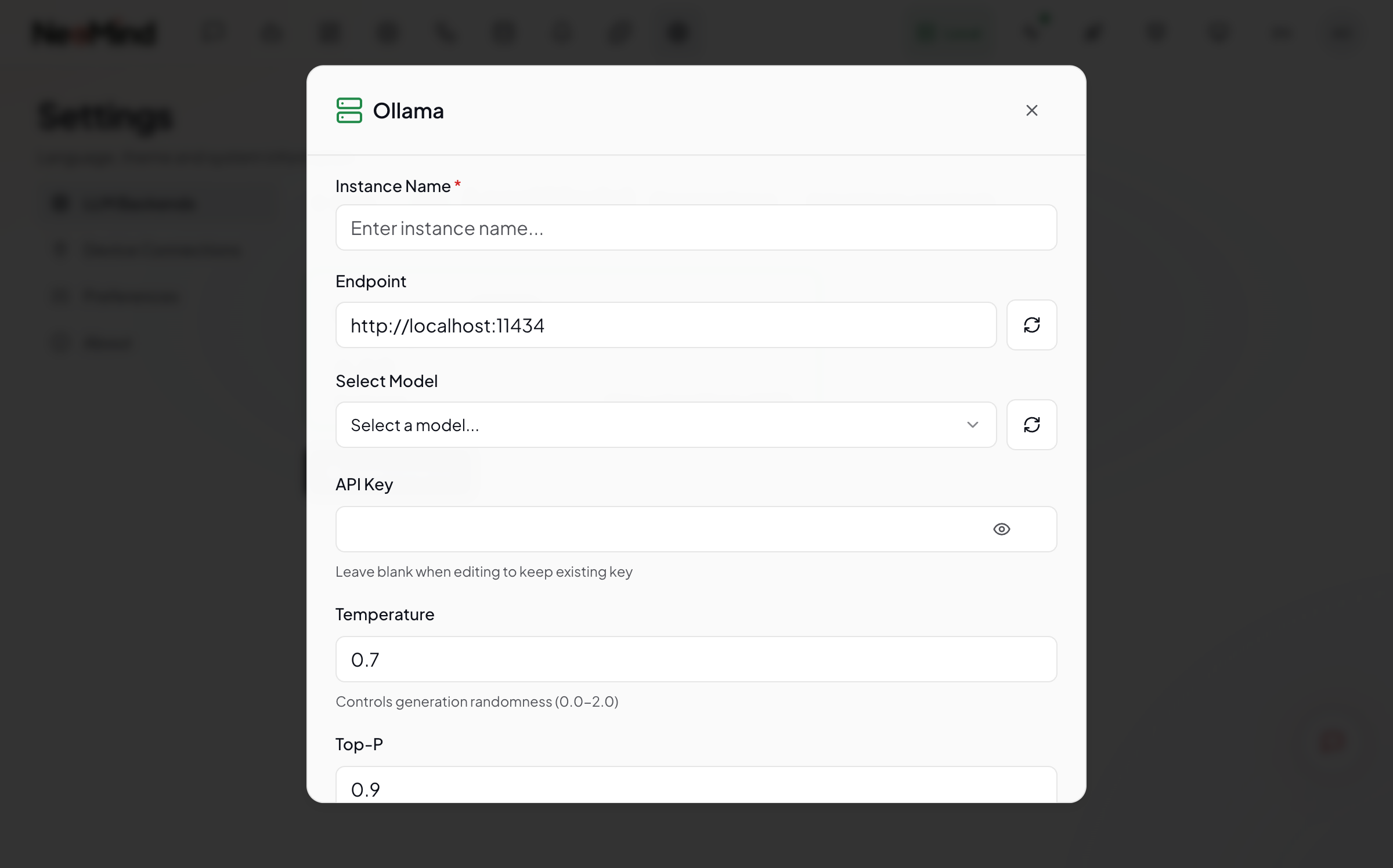
保存后 NeoMind 会探测后端能力(工具调用、多模态、上下文窗口),自动写入能力标签。
Step 4:设为默认并验��证
在后端列表中点击 Set Default(设为默认) 将其设为系统默认后端。
然后进入 AI Chat 发送一句问候验证:
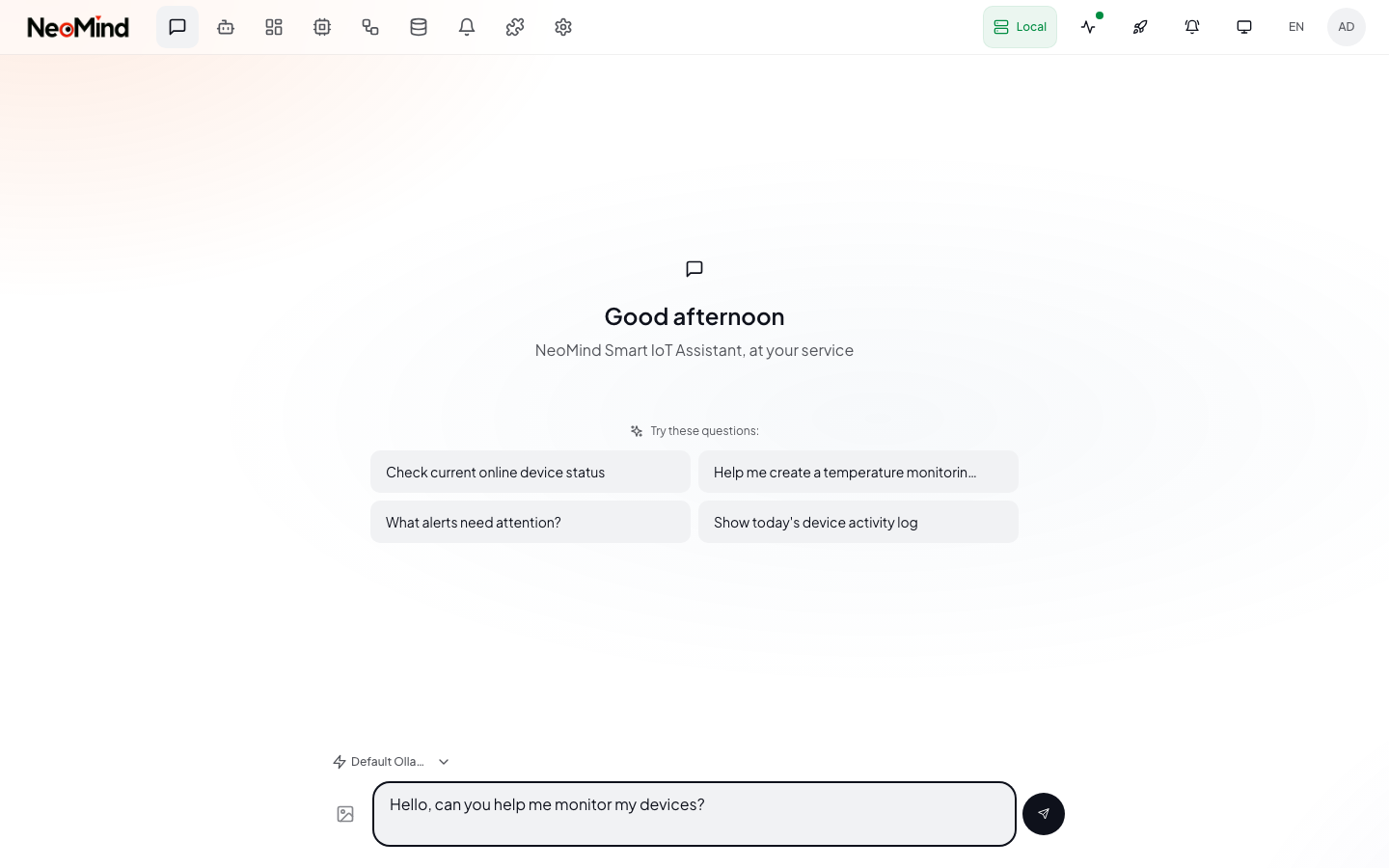
如果 AI Chat 无响应,检查:
- Ollama 是否在运行:
ollama list应能看到已拉取的模型- 云端后端:API Key 是否有效、网络是否通
- 更多见 故障排查
方式二:CLI 配置
不想点界面?以下命令完成从创建到激活的全流程。
1. 查看现有后端
neomind llm list
2. 查看可用模型(Ollama)
# 列出 Ollama 已拉取的模型
neomind llm models
# 或指定远程 Ollama
neomind llm models --endpoint http://192.168.1.100:11434
3. 创建后端
# Ollama 本地
neomind llm create --name local --type ollama \
--endpoint http://localhost:11434 --model qwen3.5:4b
# OpenAI 云端
neomind llm create --name openai --type openai \
--endpoint https://api.openai.com/v1 \
--model gpt-4o-mini --api-key sk-xxxx
# GLM 云端�(OpenAI 兼容)
neomind llm create --name glm --type openai \
--endpoint https://open.bigmodel.cn/api/paas/v4 \
--model glm-4-flash --api-key xxx.xxx.xxx
# 自定义网关(OpenRouter 等)
neomind llm create --name router --type custom \
--endpoint https://openrouter.ai/api/v1 \
--model anthropic/claude-3.5-sonnet --api-key sk-or-xxxx
创建成功会返回后端 ID(如 local 或随机 ID)。
4. 测试连接
neomind llm test local
返回模型信息和响应状态 = 连接正常。
5. 设为默认
neomind llm activate local
6. 其他常用命令
# 查看后端详情(含能力标签)
neomind llm get local
# 更新模型或参数
neomind llm update local --model qwen3.5:8b --temperature 0.5
# 删除后端
neomind llm delete local
📖 CLI 参数速查
| 命令 | 说明 | 关键参数 |
|---|---|---|
llm list | 列出所有后端 | --json 输出 JSON |
llm get <id> | 查看详情 | — |
llm models | 列出 Ollama 可用模型 | --endpoint <url> |
llm create | 创建后端 | --name --type --endpoint --model --api-key --temperature |
llm update <id> | 更新配置 | --model --endpoint --api-key --temperature |
llm test <id> | 测试连接 | — |
llm activate <id> | 设为默认 | — |
llm delete <id> | 删除 | — |
Ollama API 端点说明
NeoMind 调用 Ollama 的原生 /api/chat 端点(不是 /v1/chat/completions)。这意味着:
- 支持
thinking字段(推理类模型如 qwen3.x / deepseek-r1 的思维链) - 支持原生多模态(图像输入)
- 流式输出与工具调用走 Ollama 原生协议
如果你在自测时用 curl,请注意调用正确的端点:
curl http://localhost:11434/api/chat -d '{
"model": "qwen3.5:4b",
"messages": [{"role": "user", "content": "你好"}],
"stream": false
}'
多模��态(视觉)能力
NeoMind 支持图像输入与视觉分析。视觉能力的启用取决于模型:
- Ollama:拉取视觉模型(如
qwen3.5:4b-vl/llava/minicpm-v)后,在 AI Chat 中可直接上传图片提问。 - 云端:
gpt-4o/gpt-4o-mini/claude-3-5-sonnet/gemini-1.5-flash/qwen-vl/glm-4v等天然支持视觉。
NeoMind 会自动探测模型的多模态能力(通过 LiteLLM 注册表 + /api/show 运行时探测 + 名称启发式匹配)。如果自动探测不准,可在后端详情页手动覆盖 Multimodal 开关。
设置默认后端
一个 NeoMind 实例可配置多个 LLM 后端,但只有一个被标记为默认。默认后端用于:
- AI Chat 的初始对话
- 计划型 Agent 的执行
- 规则引擎中的 LLM 分析
- Web UI:后端列表 → 点 Set Default
- CLI:
# 查看所有后端及当前默认
neomind llm list
# 将指定后端设为默认
neomind llm activate local
下一步
最后更新: 2026-06-15